Les contrainesles dépendances fonctionnelles
Première catégorie des contraintes d'intégrité, les dépendances fonctionnelles ou DF représentent un concept primordial à la base de la théorie de la conception des bases de données.
"Une bien belle phrase, mais ça ne m'avance pas pour autant ça"
Elles permettent de définir formellement la notion de bons schémas, c'est-à-dire de schémas de bases de données pour lesquels il n'existe pas d'anomalies lors de mises à jour (MAJ), d'insertions, de modifications, ou de suppressions de tuples.
Elles généralisent la notion de clé des SGBD (c'est-à-dire
clé primaire, contrainte d'unicité).Rien de tel une nouvelle fois qu'un bon exemple pour comprendre.
Soit U = {id, nom, adresse, cnum, desc, note} un univers décrivant des étudiants et des cours.
Soit le schéma de BD suivant :
R1 = {Donnees} avec schema(Donnees) = U
Comment peut-on évaluer ce schéma de bases de données? Est-il bon? Pourquoi est-il ou n'est-il pas bon?Soit le schéma de BD suivant :
R1 = {Donnees} avec schema(Donnees) = U
Toutes ces questions il faut vous les poser à chaque fois que vous créez une base de données.
Voilà comment on peut répondre à ces questions.
Pour bien vous faire comprendre le fonctionnement, je vais vous filer une table représentant cette base de données
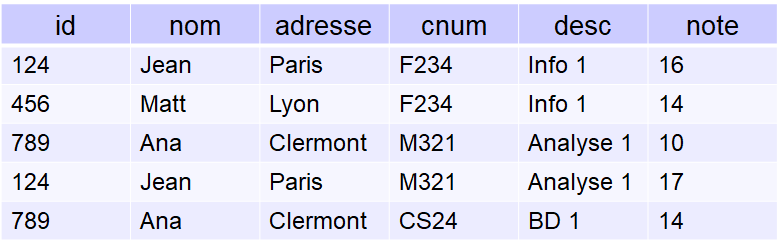
Est-ce un bon schéma?

Mais pourquoi donc ce n'est pas un bon schéma? Quels sont les problèmes?
Déjà, premier souci, la redondance de l'information:
Regardons notre tableau, on remarque que l'information "124, Jean, Paris" apparaît dans deux lignes différentes
⇒ c'est ce qu'on appelle une anomalie de modification. Elle implique que si je veux faire une modification sur une ligne, cela peut nécessiter des modifications sur d'autres lignes.
Deuxième souci, Certaines informations dépendent de l'existence d'autres informations
Le cours"CS24, BD 1" dépend de l’existence d'Ana
⇒ c'est ce qu'on appelle une anomalie de suppression. Elle implique que si je veux faire disparaître Ana (vous choisissez le moyen qui vous plaira, ce n'est pas mon souci), cela implique la disparition du cours de BD, et ça, c'est moche.
Enfin troisième souci, les soucis de création de l'information:
Un nouvel élève débarque en ville, "’145, Bob, Theix"On ne peut l'insérer que si l’on connait un de ses cours et sa note dans ce cours, à moins de permettre les valeurs nulles.
⇒ c'est ce qu'on appelle une anomalie d'insertion. Elle implique que si je veux créer une nouvelle ligne, alors il me faut toutes les informations pour pour pouvoir la remplir.
Syntaxe et sémantique des DF
Une DF sur un schéma R est une déclaration de la forme :R : X → Y , où X, Y ∈ schema(R)Une DF R : X → Y est satisfaite par une relation r sur R, noté r ╞ X → Y , si et seulement si ∀ t1,t2 Є r si t1[X] = t2[X] alors t1[Y] = t2[Y]
En bon français, ça veut dire que pour un attribut X qui a une valeur x1 donnée pour un tuple, on aura un attribut Y avec une valeur y1. Et donc, si on retrouve dans un autre tuple la valeur x1 pour X, alors on aura forcément y1 pour Y.
En bon français+++, imaginons qu'on a pour une ligne Nom='Reichstadt' et Prénom='Matthieu', alors si sur une autre ligne on a Nom='Reichstadt' Prénom aura forcément pour valeur 'Matthieu'
Exemple: Que pensez-vous de ces deux assertions ?
Donnees ╞ id → nom, adresse
Donnees ╞ id → note
Donnees ╞ id → nom, adresse
Donnees ╞ id → note
Comment construire une BD sur R2 à partir de R1?
Et bien il faut trouver les bonnes DF, et à partir de là, construire plusieurs tables.Retour sur la notion de clé
Les clés sont des cas particuliers de dépendances fonctionnelles.Soit F un ensemble de DF sur R, on va pouvoir définir ce que l'on appelle une
supercléUn ensemble d’attributs X ⊆ schema(R) est une superclé de R par rapport à F si X → schema(R) peut se déduire de F
Mais alors qu'est-ce qu'une
clé? Un ensemble d’attributs X ∈ schema(R) est une clé (ou clé minimale) pour F si et seulement si X est une superclé de R et ∄ Y ⊂ X, Y superclé de R.
Autrement dit, si X est une clé de r, il ne peut pas exister deux tuples de r ayant la même valeur sur X.